July 31, 2011
Older: Counters Everywhere
Newer: Stupid Simple Debugging
Counters Everywhere, Part 2
In Counters Everywhere, I talked about how to handle counting lots of things using single documents in Mongo. In this post, I am going to cover the flip side—counting things when there are an unlimited number of variations.
Force the Data into a Document Using Ranges
Recently, we added window and browser dimensions to Gaug.es. Screen width has far fewer variations as there are only so many screens out there. However, browser width and height can vary wildly, as everyone out there has there browser open just a wee bit different.
I knew that storing all widths or heights in a single document wouldn’t work because the number of variations was too high. That said, we pride ourselves at Ordered List on thinking through things so our users don’t have to.
Does anyone really care if someone visited their site with a browser open exactly 746 pixels wide? No. Instead, what matters is what ranges of widths are visiting their site. Knowing this, we plotted out what we considered were the most important ranges of widths (320, 480, 800, 1024, 1280, 1440, 1600, > 2000) and heights (480, 600, 768, 900, > 1024).
Instead of storing each exact pixel width, we figure out which range the width is in and do an increment on that. This allows us to receive a lot of varying widths and heights, but keep them all in one single document.
{
"sx" => {
"320" => 237,
"480" => 367,
"800" => 258,
"1024" => 2273,
"1280" => 10885,
"1440" => 6144
"1600" => 13607,
"2000" => 2154,
},
"bx" => {
"320" => 121,
"480" => 390,
"800" => 3424,
"1024" => 9790,
"1280" => 11125,
"1440" => 3989
"1600" => 6757,
"2000" => 301,
},
"by" => {
"480" => 3940,
"600" => 13496,
"768" => 8184,
"900" => 6718,
"1024" => 3516
},
}I would call this first method for storing a large number of variations cheating, but in this instance, cheating works great.
When You Can’t Cheat
Where the single document model falls down is when you do not know the number of variations, or at least know that it could grow past 500-1000. Seeing how efficient the single document model was, I tried to store content and referrers in the same way, initially.
I created one document per day per site and it had a key for each unique piece of content or referring url with a value that was an incrementing number of how many times it was hit.
It worked great. Insanely small storage and no secondary indexes were needed, so really light on RAM. Then, a few larger sites signed up that were getting 100k views a day and had 5-10k unique pieces of content a day. This hurt for a few reasons.
First, wildly varying document sizes. Mongo pads documents a bit, so they can be modified without moving on disk. If a document grows larger than the padding, it has to be moved. Obviously, the more you hit the disk the slower things are, just as the more you go across the network the slower things are. Having some documents with 100 keys and others with 10k made it hard for Mongo to learn the correct padding size, because there was no correct size.
Second, when you have all the content for a day in one doc and have to send 10k urls plus page titles across the wire just to show the top fifteen, you end up with some slowness. One site consistently had documents that were over a MB in size. I quickly realized this was not going to work long term.
In our case, we always write data in one way and always read data in one way. This meant I needed an index I could use for writes and one that I could use for reads. I’ll get this out of the way right now. If I had it to do over again, I would definitely do it different. I’m doing some stupid stuff, but we’ll talk more about that later.
The keys for each piece of content are the site_id (sid), path (p), views (v), date (d), title (t), and hash (h). Most of those should be obvious, save hash. Hash is a crc32 of the path. Paths are quite varying in length, so indexing something of consistent size is nice.
For writes, the index is [[‘sid’, 1], [‘d’, -1], [‘h’, 1]] and for reads the index is [[‘sid’, 1], [‘d’, -1], [‘v’, -1]]. This allows me to upset based on site, date and hash for writes and then read the data by site, date and views descending, which is exactly what it looks like when we show content to the user.
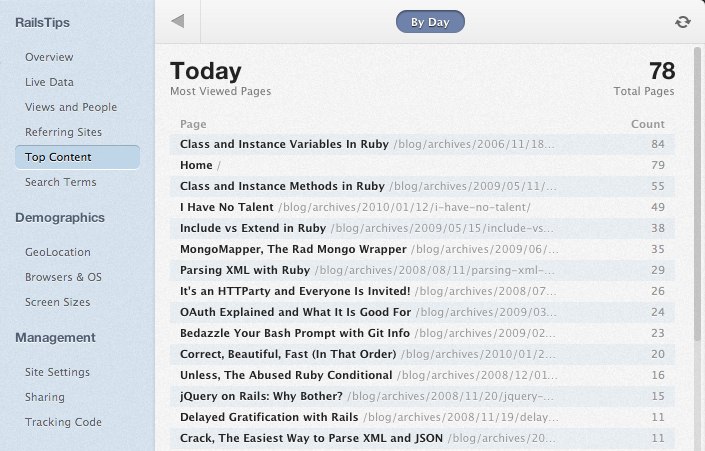
As mentioned in the previous post, I do a bit of range based partitioning as well, keeping a collection per month. Overall, this is working great for content, referrers and search terms on Gaug.es.
Learning from Mistakes
So what would I do differently if given a clean slate? Each piece of content and referring url have an _id key that I did not mention. It is never used in any way, but _id is automatically indexed. Having millions of documents each month, each with an _id that is never used starts to add up. Obviously, it isn’t really hurting us now, but I see it as wasteful.
Also, each document has a date. Remember that the collection is already partitioned by month (i.e.: c.2011.7 for July), yet hilariously, I store the full date with each document like so: yyyy-mm-dd. 90% of that string is completely useless. I could more easily store the day as an integer and ignore the year and month.
Having learned my lesson on content and referrers, I switched things up a bit for search terms. Search terms are stored per month, which means we don’t need the day. Instead of having a shorter but meaningless _id, I opted to use something that I knew would be unique, even though it was a bit longer.
The _id I chose was “site_id:hash” where hash is a crc32 of the search term. This is conveniently the same as the fields that are upserted on, which combined with the fact that _id is always indexed means that we no longer need a secondary index for writes.
I still store the site_id in the document so that I can have a compound secondary index on site_id (sid) and views (v) for reads. Remember that the collection is scoped by month, and that we always show the user search terms for a given month, so all we really need is which terms were viewed the most for the given site, thus the index is [[‘sid’, 1], [‘v’, -1]].
Hope that all makes sense. The gist is rather than have an _id that is never used, I moved the write index to _id, since it will always be unique anyway, which means one less secondary index and no wasted RAM.
Interesting Finding
The only other interesting thing about all this is our memory usage. Our index size is now ~1.6GB, but the server is only using around ~120MB of RAM. How can that be you ask? We’ve all heard that you need to have at least as much RAM as your index size, right?
The cool thing is you don’t. You only need as much RAM as your active set of data. Gaug.es is very write heavy, but people pretty much only care about recent data. Very rarely do they page back in time.
What this means is that our active set is what is currently being written and read, which in our case is almost the exact same thing. The really fun part is that I can actually get this number to go up and down just by adjusting the number of results we show per page for content, referrers and search terms.
If we show 100 per page, we use more memory than 50 per page. The reason is that people click on top content often to see what is doing well, which continually loads in the top 100 or 50, but they rarely click back in time. This means that the active set is the first 100 or 50, depending on what the per page is. Those documents stay in RAM, but older pages get pushed out for new writes and are never really requested again.
I literally have a graph that shows our memory usage drop in half when we moved pagination from the client-side to the server-side. I thought it was interesting, so figured I would mention it.
As always, if you aren’t using Gaug.es yet, be sure to give the free trial a spin!

3 Comments
Aug 01, 2011
This stuff is really fascinating. Thanks for sharing.
Sep 01, 2011
Thanks for your work on this and MongoMapper. I’m a new user of gaug.es and mm and am loving both.
Sep 01, 2011
@James – You are welcome!
Sorry, comments are closed for this article to ease the burden of pruning spam.